
Bimanual coordination is essential for many real-world manipulation tasks, yet learning bimanual robot policies is limited by the scarcity of bimanual robots and datasets. Single-arm robots, however, are widely available in research labs. Can we leverage them to train bimanual robot policies?
We present MonoDuo, a framework for learning bimanual manipulation policies using single-arm robot demonstrations paired with human collaboration. MonoDuo collects data by teleoperating a single-arm robot to perform one side of a bimanual task while a human performs the other, then swapping roles to cover both sides. RGB-D observations from a wrist-mounted and fixed camera are augmented into synthetic demonstrations for target bimanual robots using state-of-the-art hand pose estimation, image and point cloud segmentation, and inpainting. These synthetic demonstrations, grounded in real robot kinematics, are used to train bimanual policies.
We evaluate MonoDuo on five tasks—box lifting, backpack packing, cloth folding, jacket zipping, and plate handover. Compared to approaches relying solely on human bimanual videos, MonoDuo enables zero-shot deployment on unseen bimanual robot configurations, achieving success rates up to 70%. With only 25 target robot demonstrations, few-shot finetuning further boosts success rates by 65-70% over training from scratch, demonstrating MonoDuo's effectiveness in efficiently transferring knowledge from single-arm robot data to bimanual robot policies.

Our teleoperation system uses a fixed RGB-D camera and a wrist-mounted camera. We teleoperate a single-arm robot to collaborate with a human arm on a bimanual task, alternating left-right arm roles across episodes. This results in complementary interaction data covering both sides of the task. These human-robot bimanual demonstrations are then augmented into synthetic robot-robot bimanual demonstrations to create a visually and physically grounded dataset for training bimanual robots.
Below are samples of collected demonstration data for five tasks: Fold Cloth, Plate Handover, Zip Jacket, Lift Box, and Pack Back.
Examples of our human-robot data collection across various tasks.
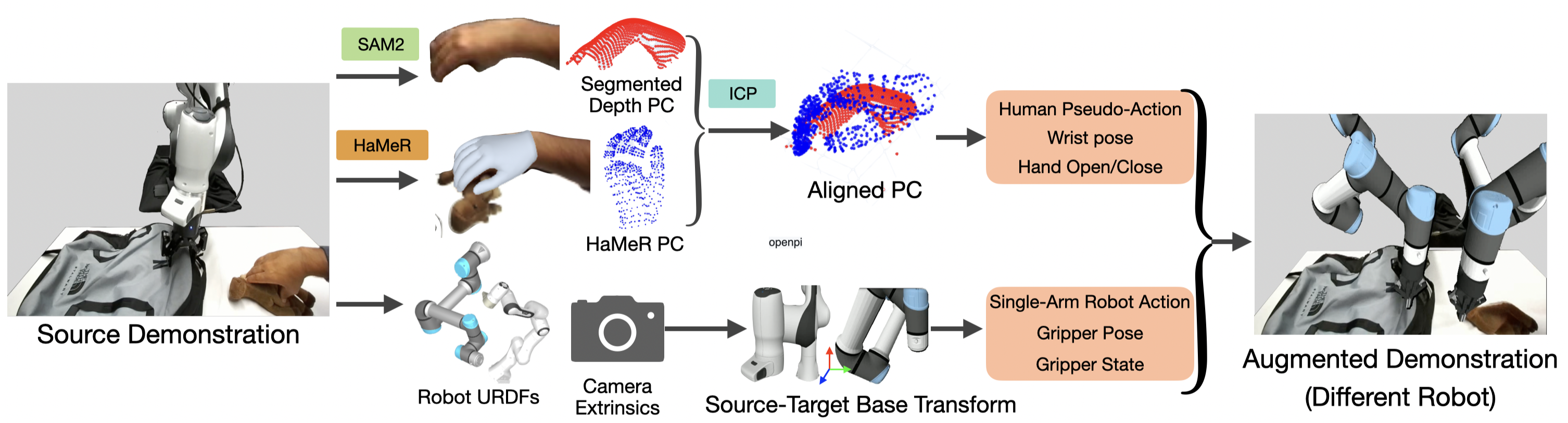
Left: We apply HaMeR to estimate the hand pose at each frame and refine with ICP. The refined hand pose is then retargeted into robot end-effector actions in the source dataset. Right: We perform cross-painting from both the source robot and the human arm to the target robot.
Rollout videos on policy are shown below.
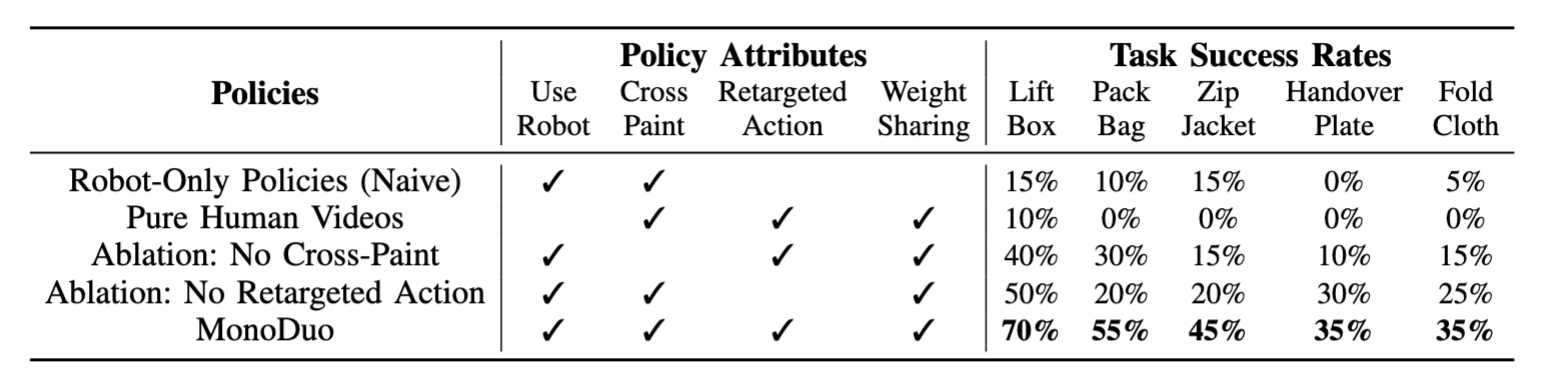
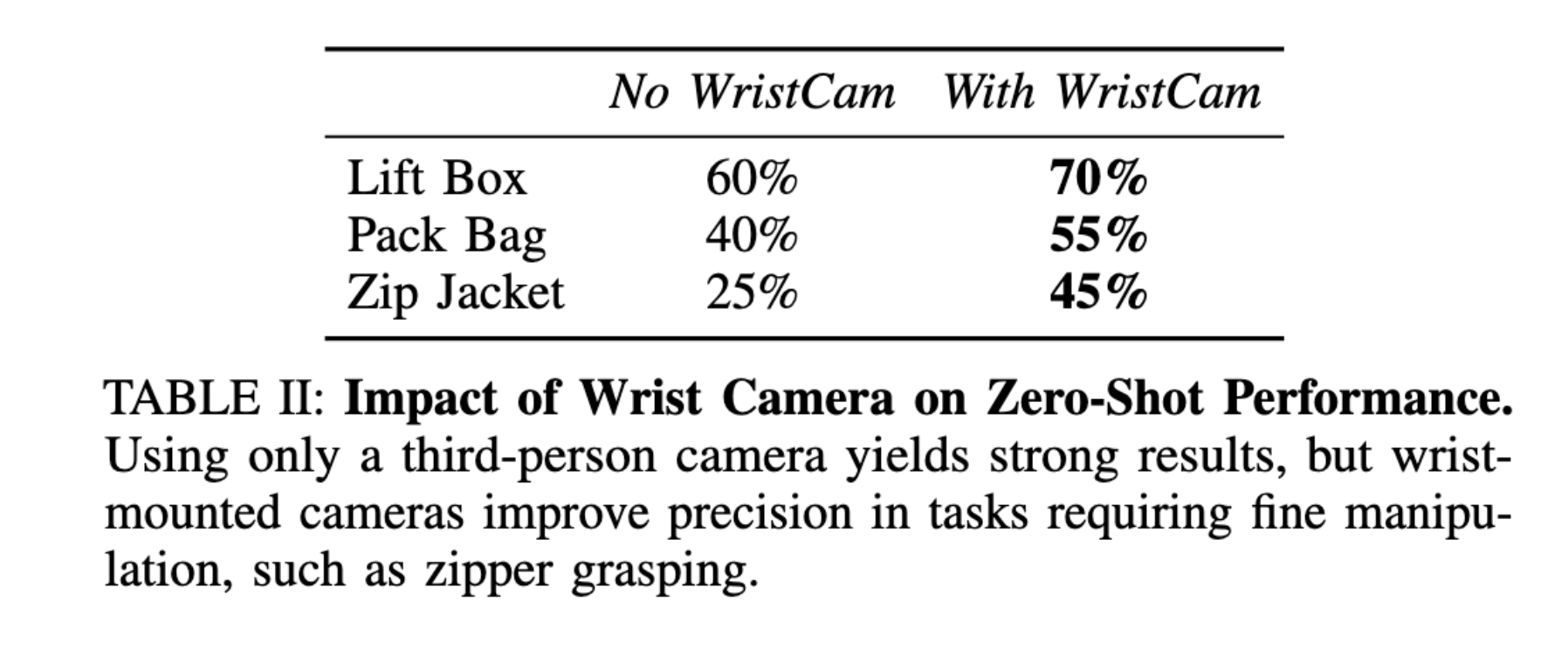
Each policy is evaluated on five manipulation tasks in a zero-shot transfer setting from Franka-human demos to a bimanual UR5e. We collect and train on 200 Franka-human demos per task. The results are shown below. The following show that MonoDuo is able to effectively bridge both the visual and physical gaps among different robots and human, allowing one to learn bimanual policies when only a single-arm robot is available.
MonoDuo achieves strong zero-shot bimanual manipulation performance despite training only from single-arm robot demonstrations. Across all five tasks, MonoDuo outperforms baselines that rely on human-only bimanual video training. The gains are most pronounced in tasks requiring complementary role coordination (e.g., zip jacket and pack backpack), highlighting the value of robot-grounded interaction data.
Additionally, when limited target-robot demonstrations (25 per task) are available, few-shot finetuning dramatically improves success rates. This shows that MonoDuo is not only effective for zero-shot transfer, but also provides a strong initialization for rapid adaptation to new bimanual setups.

@misc{bajamahal2025monoduo,
title={MonoDuo: Using One Robot Arm to Learn Bimanual Policies},
author={Sandeep Bajamahal and Lawrence Yunliang Chen and Toru Lin and Zehan Ma and Jitendra Malik and Ken Goldberg},
year={2025},
eprint={},
archivePrefix={arXiv},
primaryClass={cs.RO},
url={/mnt/data/MonoDuo_Public_v1.pdf}
}